在我們之前的文章中,無論是摘要、例句推薦等,都是用固定的資料來模擬各種情境。但現實世界的應用遠比這複雜。接下來的幾篇文章,我們將帶領大家更深入地了解如何處理真實世界中的外部資料。
一般來說,聊天機器人不僅依賴語言模型來生成對話,還需要整合各種外部資料來提供更全面的服務。這是因為語言模型本身並不包含所有可能需要的知識。這個整合過程通常被稱為 RAG(Retrieval Augmented Generation,檢索增強生成),其重要的流程如下: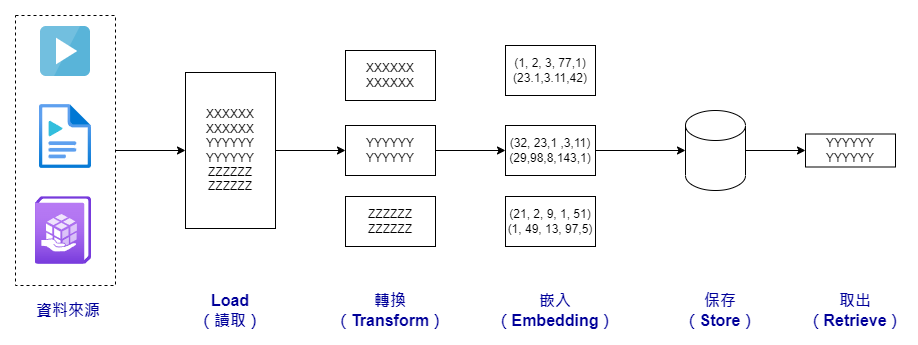
首先,我們有一個統稱為「Loader」的程序。在 LangChain 框架中,它提供給我們非常多樣,不同文件類型的 Loader,這類模組主要負責讀取各種外部資料,然後將其轉換成 LangChain 的通用資料結構,也就是「Document」。
接著,我們會對這些讀取進來的資料進行一些轉換。比如,如果我們要從一個影片中提取資料,我們可能會隨機選取三個例句作為資料來源。或者,如果文件太大,超過了語言模型一次能處理的範圍,我們會將它切割成更小的部分。
第三步是進行所謂的「嵌入(Embedding)」運算。這個運算會將文檔轉換成一個向量,這個向量能夠代表文檔的內容特性。這樣的向量可以用於各種語言處理任務,比如文字聚類。通常,我們會將這些向量儲存到一個專門的資料庫中。
最後,根據實際需求,我們會從這些儲存的資料中提取必要的信息,以便進行更進一步的應用。
LangChain 框架幸運地支持了上述所有的 RAG 流程。在接下來的文章中,我們將逐一為大家詳細介紹這些流程。由於篇幅限制,今天我們將重點介紹如何使用 LangChain 框架來讀取 YouTube 字幕檔,以及如何進行文件轉換。
幾天前,我們已經向大家介紹了 LangChain 的一個文件讀取器,名為 TextLoader。今天,我們將繼續介紹 LangChain 的另一個內建讀取器:SRTLoader。這個讀取器的使用方式與 TextLoader 相當類似。不過,SRTLoader 內部實際上是利用了一個名為 pysrt 的 Python 套件來處理字幕格式的細節。因此,在開始使用之前,我們需要先安裝這個套件。安裝指令如下:
!pip install pysrt
安裝完成後,我們就可以使用以下的程式碼來讀取預先下載的字幕檔:
from langchain.document_loaders import SRTLoader, TextLoader
loader = SRTLoader(
'/content/ironman2023/srt_files/World Stories to Help You Learn _ practice English with Spotlight - English.srt'
)
docs = loader.load()
print(docs)
--- 以下是實際輸出內容 ---
[Document(page_content='Welcome to Spotlight. I’m Adam Navis...中間省略...the next Spotlight program. Goodbye!', metadata={'source': '/content/ironman2023/srt_files/World Stories to Help You Learn _ practice English with Spotlight - English.srt'})]
從 TextLoader 和 SRTLoader 的輸出結果來看,LangChain 框架會將所有讀取到的文檔統一轉換為 Document 結構。這個結構還包含一個 metadata 屬性,用於存儲額外的資訊。例如,讀取器會將其獲取的檔案來源記錄在 metadata 的 source 欄位中,甚至如稍後我們在 RecursiveCharacterTextSplitter 介紹中會使用到的,記錄字串分割的位置資訊等。
資料轉換的部分,我們今天要來跟大家介紹三個我們這次實做時會使用到的文字分隔器: CharacterTextSplitter、RecursiveCharacterTextSplitter 以及 TokenTextSplitter。
讀取完文檔後,我們通常會進行進一步的加工,例如文本的分割、合併或過濾等。這些都屬於「文件轉換」的範疇。LangChain 提供了這方面的多種支援。
雖然文件的分割和合併聽起來很簡單,但實際上可能涉及到許多複雜的邏輯。例如,我們如何確保相關的資料能夠被一起分割?或者,在分割過程中,如何避免重要資訊的丟失等,這些細節我們都會在接下來這幾天的篇幅跟大家接受,今天,我們則先跟大家介紹三個我們這次實做時會使用到的文字分隔器: CharacterTextSplitter、RecursiveCharacterTextSplitter 以及 TokenTextSplitter。
LangChain 提供了多種文本分割器,其中 RecursiveCharacterTextSplitter 是 LangChain 預設而且我們非常推薦的選項。這個分割器會根據指定的「段落大小目標」(chunk_size)和「重疊字元數」(chunk_overlap)來分割文本,實際的使用程式碼如下:
from langchain.text_splitter import RecursiveCharacterTextSplitter
recursive_text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 50,
chunk_overlap = 10,
length_function = len,
add_start_index = True,
)
recursive_splitted_texts = recursive_text_splitter.create_documents([docs[0].page_content])
print(f'len of recursive_splitted_texts: {len(recursive_splitted_texts)}')
for (idx, t) in enumerate(recursive_splitted_texts[:3]):
print(f'Doc {idx} - text len: {len(t.page_content)}, page_content: {t.page_content}')
--- 輸出結果 ---
len of recursive_splitted_texts: 185
Doc 0 - text len: 47, page_content: Welcome to Spotlight. I’m Adam Navis. Spotlight
Doc 1 - text len: 24, page_content: Spotlight uses a special
Doc 2 - text len: 48, page_content: English method of broadcasting. It is easier for
這個分割器預設會使用 ["\n\n", "\n", " ", ""] 這組字串來進行文本的分割。它會先嘗試使用第一個分割字元(例如 "\n\n")來分割文本。如果分割後的段落仍然太大,它會嘗試使用下一個分割字元(例如 "\n"),直到達到我們設定的大小限制。
你可能會好奇,為什麼需要一個「重疊字元數」(chunk_overlap)的設定。其實,這個設計是非常有用的。有了這個重疊區域,我們可以在一定程度上保留冗餘的資訊。換句話說,這個重疊區域可以作為一個資訊的「緩衝區」。
舉例來說,想像你正在閱讀一本書,每次你只能看一頁。當你翻到下一頁時,如果前一頁的最後一句話和下一頁的第一句話有所連接,但你已經忘記了前一頁的內容,這會讓你感到困惑。但如果每一頁的開頭都重複了前一頁的最後幾行,這樣你就可以更容易地理解故事的連續性。這就是「重疊區域」的概念,它確保了資訊的連續性和完整性,避免了可能的資訊斷層。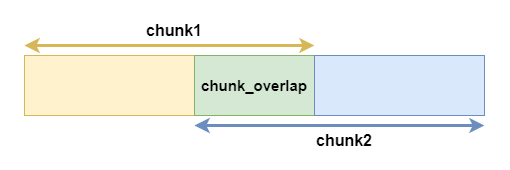
最後,length_function 這個參數允許我們自定義如何計算文本的「長度」。預設情況下,它會使用 Python 的 len 函式來計算,但你也可以根據需要來自己定義。
CharacterTextSplitter 是一個相對簡單的文本分割器,它只允許你指定一個分割字串。例如,它的預設分割字串是 "\n\n",這通常用於段落之間的分割。為什麼會這樣設計呢?因為在不同的段落之間,我們通常會加入一個額外的換行符號(newline)來讓文本更容易閱讀,然而,由於我們範例的文本是從字幕檔讀取而來,這樣的結構就不太適合使用它預設的方式來做分割,所以我們改指定為一個換行字元來做分割字串來進行作業,如下:
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n",
chunk_size = 50,
chunk_overlap = 10,
length_function = len,
add_start_index = True,
)
splitted_texts = text_splitter.create_documents([docs[0].page_content])
print(f'len of recursive_splitted_texts: {len(splitted_texts)}')
for (idx, t) in enumerate(splitted_texts[:3]):
print(f'Doc {idx} - text len: {len(t.page_content)}, page_content: {t.page_content}')
--- 分割結果 ---
len of recursive_splitted_texts: 60
Doc 0 - text len: 62, page_content: Welcome to Spotlight. I’m Adam Navis. Spotlight uses a special
Doc 1 - text len: 70, page_content: English method of broadcasting. It is easier for people to understand,
Doc 2 - text len: 126, page_content: no matter where in the world they live. We begin today’s program with a story. Kwesuka sukela - once upon a time - there lived
從分割結果可以看出,由於這個分割器只有一個分割選項(即單一的換行符號),所以它會儘量將文本分割成接近我們設定的 50 個字元的段落。例如,第一個分割出來的段落長度為 62 個字元,這是因為它沒有更多的選項來進一步細分這個段落,所以只能以最後分割後的字串來回傳。
這個分割器是非常直觀和簡單的,特別適合於需要快速、簡單分割文本的場景。然而,由於它的分割選項有限,可能不適合所有的應用場景。如果你需要更多的靈活性,可能需要考慮使用其他更高級的分割器,例如前面介紹的 RecursiveCharacterTextSplitter 。希望這樣的解釋能讓大家更容易理解這個工具的用途和限制!
最後,讓我們來談談以「token」為基礎的文本分割器,也就是 TokenTextSplitter。這個分割器的特點是它使用 OpenAI 的 tiktoken 套件作為預設的分詞器(tokenizer)。因此,在使用這個分割器之前,請確保你已經安裝了 tiktoken 套件。安裝方式非常簡單,只需要執行以下指令:
!pip install tiktoken
這個分割器的主要用途是當你希望分割後的文本段落能夠明確地遵循語言模型的 token 限制。換句話說,這是一個專為語言模型設計的分割器。下面是一個使用範例:
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)
texts = text_splitter.split_text(docs[0].page_content)
print(texts[0])
--- 輸出結果 ---
Welcome to Spotlight. I’m Adam Nav
你可能會好奇,分割後的文本是否真的符合我們設定的 token 數量。為了驗證這一點,我們可以使用 OpenAI 的 tokenizer 進行確認。實際上,"Navis" 確實被分為兩個 token:一個是 "Nav",另一個是 "is"。因此,實際的分割結果確實是 10 個 token,請見下圖視覺化的分割結果。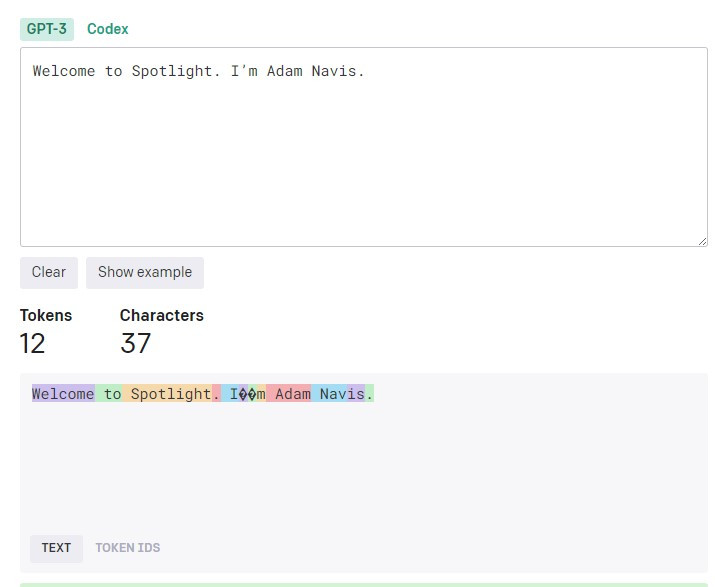
以上就是我們今天要介紹的文件轉換工具的內容,這樣的分割器設計讓你在處理大量文本時,能更精確地控制每一段文本的大小,特別是當你需要將這些文本用於語言模型時。希望這篇文章能幫助你更了解如何有效地進行文本分割。
在接下來的文章中,我們還會探討其他相關主題,如文本嵌入(Embedding)和向量資料庫等。敬請期待,而本篇文章的程式碼部分,您可以參考這裏: D20. LangChain 專案實做 - 資料的讀取與轉換.ipynb
您好,我想請問因為最後對話機器人的問答結果不盡理想(明明有提供相關資訊,但約有1/2的機率機器下會回答不知道),我使用WebBaseLoader讀取網頁內容,搭配RecursiveCharacterTextSplitter的斷詞寫入Chroma資料庫
以下是我的程式碼片斷及部分斷詞範例,是否有訣竅可以評估斷詞的品質,謝謝!
loader = WebBaseLoader(url)
text = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = chunk_size,
chunk_overlap = chunk_overlap,
)
split_texts = text_splitter.split_documents(text)
Document(page_content='本優惠之回饋金以實際回饋於信用卡帳單及正卡人指定之證券交割帳戶(限OOO帳戶)為準,回饋金適用於證券交易受扣款項等,恕不得要求折抵現金或以溢繳款方式領回。\n\n\xa0\n\nOOO保留「審核持卡人參加資格、變更或終止活動」權利,未盡事宜悉依OOO信用卡會員約定條款辦理。\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n15%回饋拿好拿滿懶人包指南'...
端看你提供的範例,它讓我直接想到的是「資料清理」或者 「Document 的整合」這方面的程序。
所謂「文件的整合」,LangChain 官方文件也有一個我個人認為收穫良多,但是我鐵人賽裏面沒有提到的內容,你也可以參考看看是否對你有助益:
https://python.langchain.com/docs/modules/chains/document/stuff
如果你需要更明確的回覆,或許你可以深入說明你想達成的目標,跟目前遇到的困境?
(以下提問可能偏離該篇主題,如有需要我可以改為站內信)
非常謝謝您的回覆,我透過verbose=True發現可能是其他問題造成機器人回覆錯誤。
我希望能達成使用自建資料庫(Chroma persistent database)設計一個信用卡主題知識答覆的機器人,並擁有對話(記憶歷史訊息)的功能。
目前遇到的困境是1.無法連續對話,2.機器人回答的內容不正確(無法正確依據資料庫內容回覆)
以下是我的程式碼片段及verbose看到的紀錄,發現機器人有誤判角色的問題,以及不確定為何產生Entering new StuffDocumentsChain chain...:
def load_model():
chat_prompt_template = PromptTemplate(
input_variables=["chat_history", "question"],
template = """
你是一個親切且優秀的聊天機器人,擁有台灣各家銀行的信用卡介紹與優惠資訊。
請依使用者提問的語言回答他的問題,預設是繁體中文。
回答內容以條列式呈現,字數最多不要超過300字。
當無法理解使用者的提問時,請引導使用者作出更詳細的提問。
當資料庫中完全沒有相關資訊時,請回答「抱歉,我目前沒有這個問題的相關資訊。您可以調整您的提問,或是詢問我其他問題。」
歷史對話紀錄:{chat_history}
使用者本次提問:{question}
"""
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
retriever = vectordb.as_retriever()
conversation_qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
verbose=True,
condense_question_prompt=chat_prompt_template
)
return conversation_qa_chain
...
history = MongoDBChatMessageHistory(
connection_string=connection_string,
session_id=sid,
database_name='credit',
collection_name='chat_history'
)
qa_database = load_model()
answer = qa_database({"question": query, "chat_history":history.messages})
history.add_user_message(query)
history.add_ai_message(answer['answer'])
> Entering new LLMChain chain...
Prompt after formatting:
你是一個親切且優秀的聊天機器人,擁有台灣各家銀行的信用卡介紹與優惠資訊。
請依使用者提問的語言回答他的問題,預設是繁體中文。
回答內容以條列式呈現,字數最多不要超過300字。
當無法理解使用者的提問時,請引導使用者作出更詳細的提問。
當資料庫中完全沒有相關資訊時,請回答「抱歉,我目前沒有這個問題的相關資訊。您可以調整您的提問,或是詢問我其他問題。」
歷史對話紀錄:
Human: 你好
Assistant: 您好!有什麼可以為您服務的地方嗎?
使用者本次提問:可以為我介紹一張信用卡嗎
> Finished chain.
> Entering new StuffDocumentsChain chain...
> Entering new LLMChain chain...
Prompt after formatting:
System: Use the following pieces of context to answer the users question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----------------
台新銀行信用卡分為「一般信用卡」...(省略)
Human: 當然可以!以下是幾家台灣銀行的信用卡介紹與優惠資訊:
1. 中國信託銀行:
- 中信銀行提供多種信用卡,包括現金回饋、航空里程、加油優惠等不同類型。
- 持有中信信用卡可以享有各種商家的折扣與優惠,例如餐廳、旅遊、購物等。
> Finished chain.
{'question': '可以為我介紹一張信用卡嗎', 'chat_history': [HumanMessage(content='你好', additional_kwargs={}, example=False), AIMessage(content='您好!有什麼可以為您服務的地方嗎?', additional_kwargs={}, example=False)], 'answer': '抱歉,我無法回答您的問題。'}


 iThome鐵人賽
iThome鐵人賽